For local development and PoCs we often use a tech stack based on Trino for query processing and Minio for storage using columnar file formats like Parquet or open table formats like Iceberg.
We believe, that this tech stack can also be used for production environments, where the offerings of vendors like Databricks or Snowflake are considered too costly.
This tech stack can easily be enhanced with tools like jupyter notebooks for data exploration and processing, dbt for enhanced automated data transformation, LakeFS for data versioning or Marquez for data lineage support.
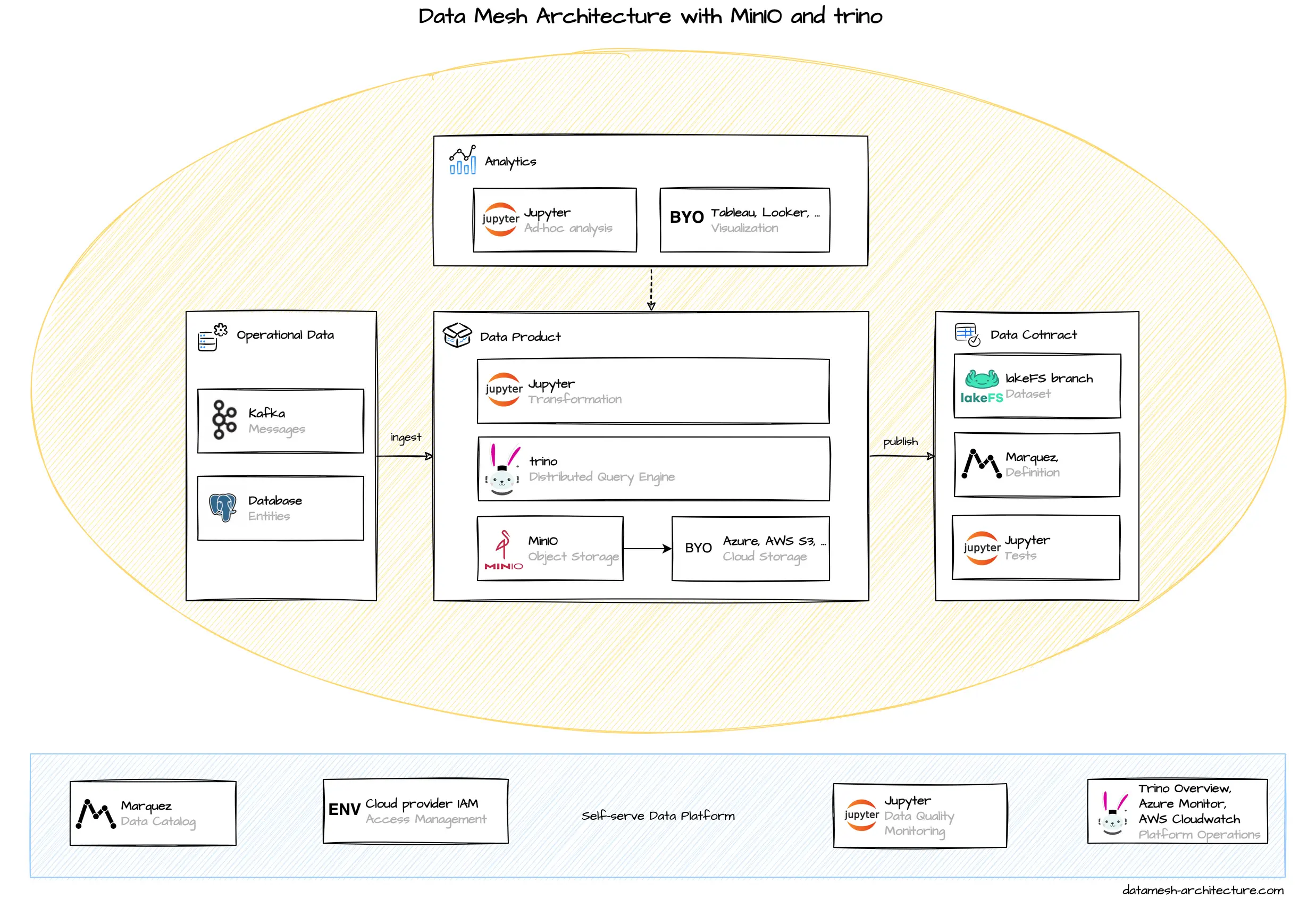
This tech stack is lightweight. We typically use docker-compose for a local deployment. A deployment based on kubernetes should be quite straightforward, but this hasn't been done by us, yet. Another deployment option would be using separate managed services like Pandio for Trino, Elestio for MinIO or JupyterHub for the notebooks.
MinIO provides a simple and high-performance s3-compatible object storage with a wide variety of deployment options.
We typically use LakeFS as an independent hierarchical file system on top of the underlying object storage. A benefit of using lakeFS is the git-like data versioning support, which we will come back to in a later section.
Trino is a distributed, highly scalable query engine, that allows to access and manipulate data from various storage systems. Trino currently relies on Hive metastore to support SQL based access to data files stored in object storage systems.
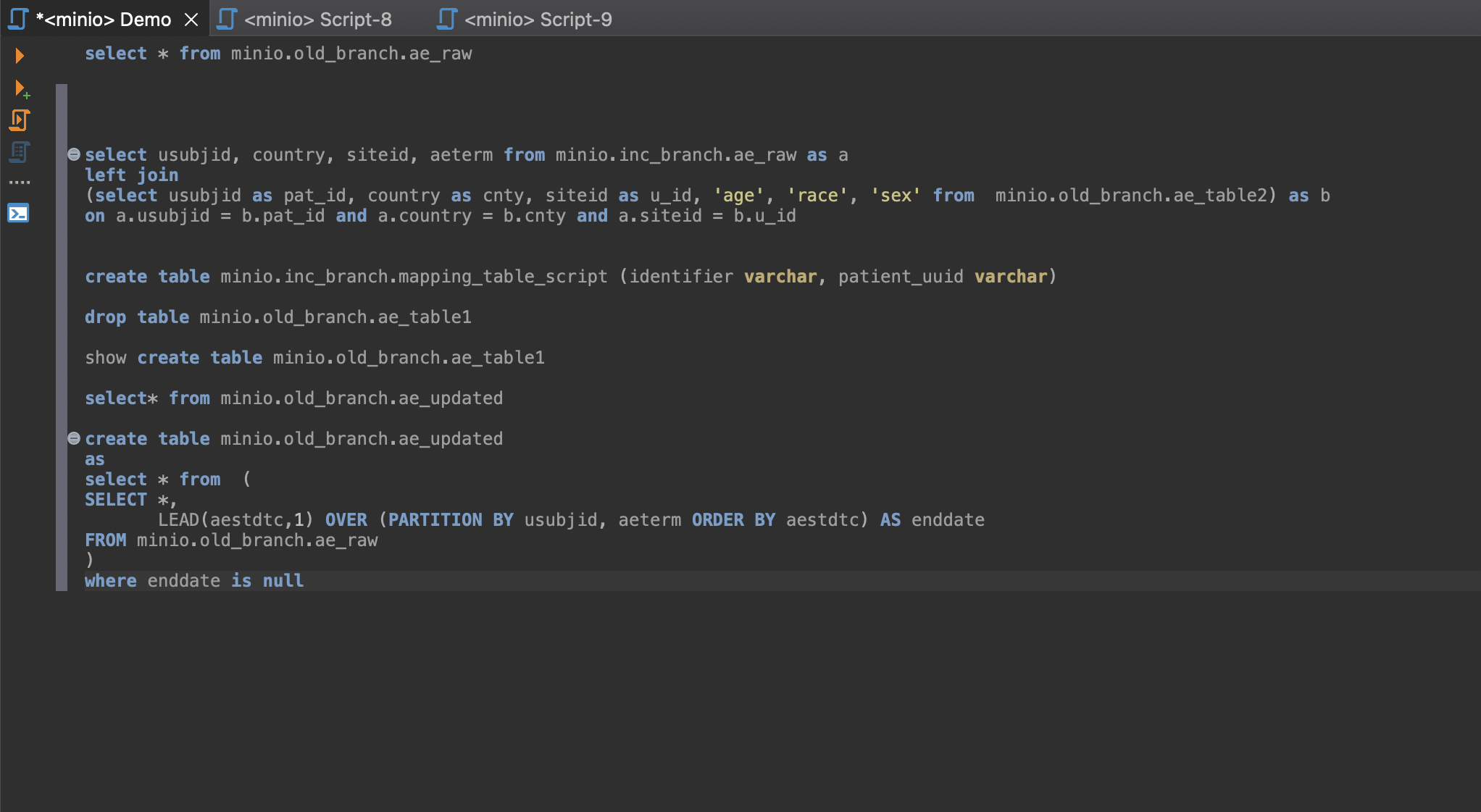
The data exploration can be done directly using the SQL data access provided by trino.
Combining jupyter notebooks with trino results in a powerful and flexible IDE for exploratory analysis leveraging both the python ecosystem and standard SQL processing.
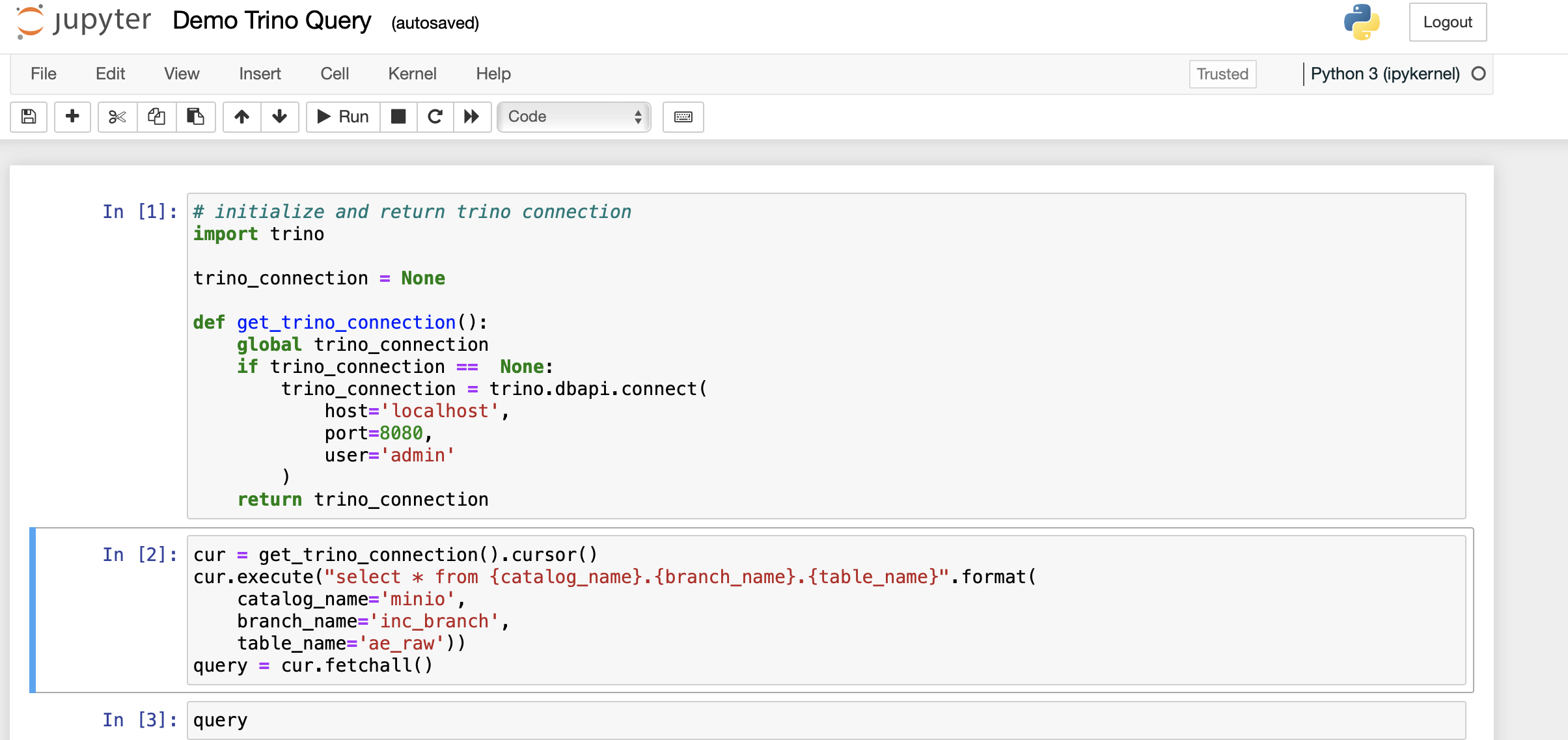
In a data mesh, every domain team provides access to their data by the use of data products. A data product can be defined as a single or a combined set of SQL tables.
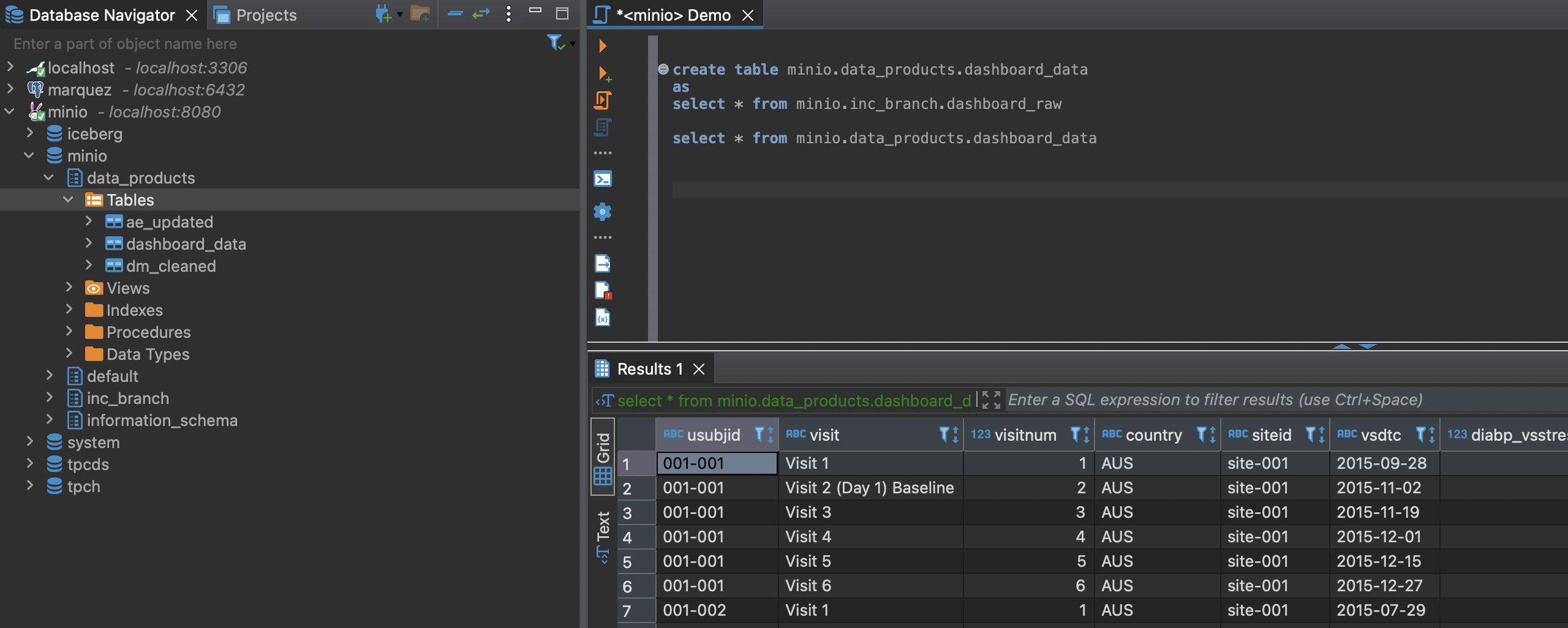
We typically use one lakeFS repository for all data products of a domain team. All of these data products are accessible through the same SQL schema.
All data files holding the data of a data product are stored in a separate directory tree in our lakeFS file system.
With trino, data products from different domains can be easily combined by using standard SQL joins.
To design a data product, we suggest a workflow that starts with the data exploration in jupyter notebooks.
When the data exploration results in useful analytical data, the necessary data processing steps can be implemented and quality approved using jupyter notebooks.
Alternatively, an additional tool like dbt can be used for this, as it makes the implementation and maintenance of data products easier.
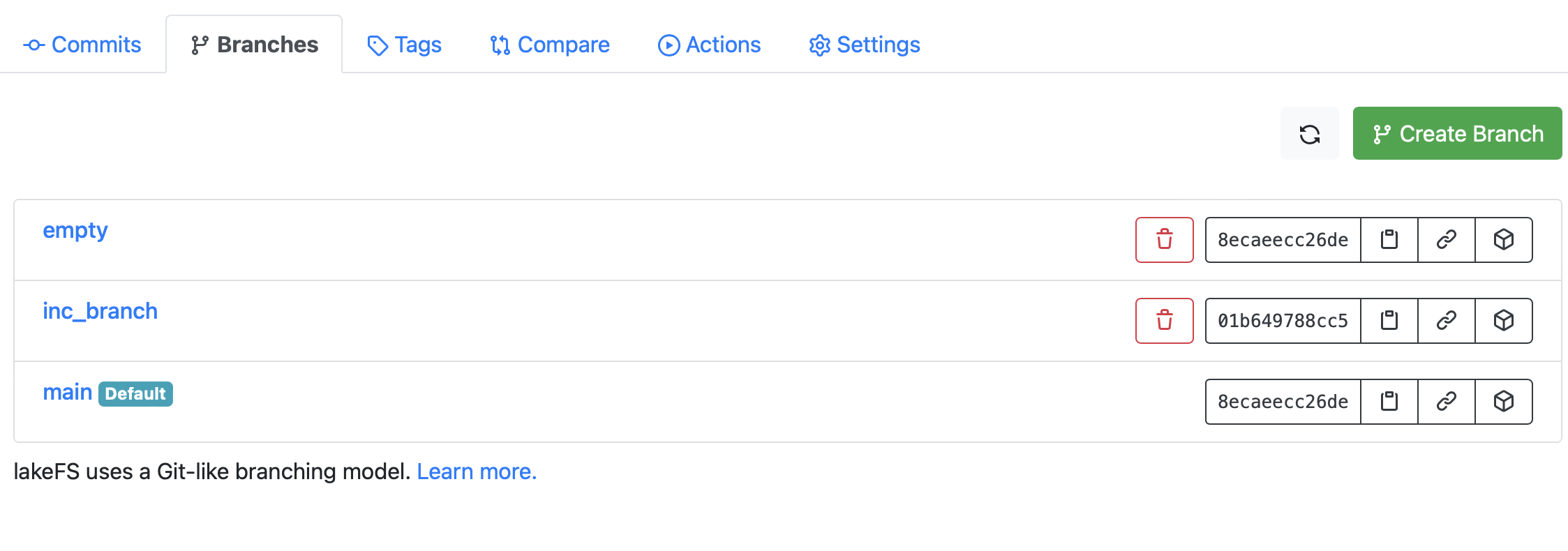
lakeFS is a git-like data versioning tool that recently has emerged high popularity.
lakeFS provides data versioning for the data in the underlying object store.
lakeFS branches support the creation of isolated snapshots of data. The data provided through a version of a data product could be stored on a specific branch.
Data files are not copied for the creation of branches, which can save a lot of storage space.
Moreover, branches make the data exploration or testing easier by reducing the risk of loosing or corrupting valuable production data.
If something goes wrong, the affected branch can just be deleted or reverted to an older state.
Branches allow to switch between different versions of a data product (time travelling).
And finally, lakeFS data versioning support can be helpful to better cope with the eventual consistency guarantees of the underlying object storage.
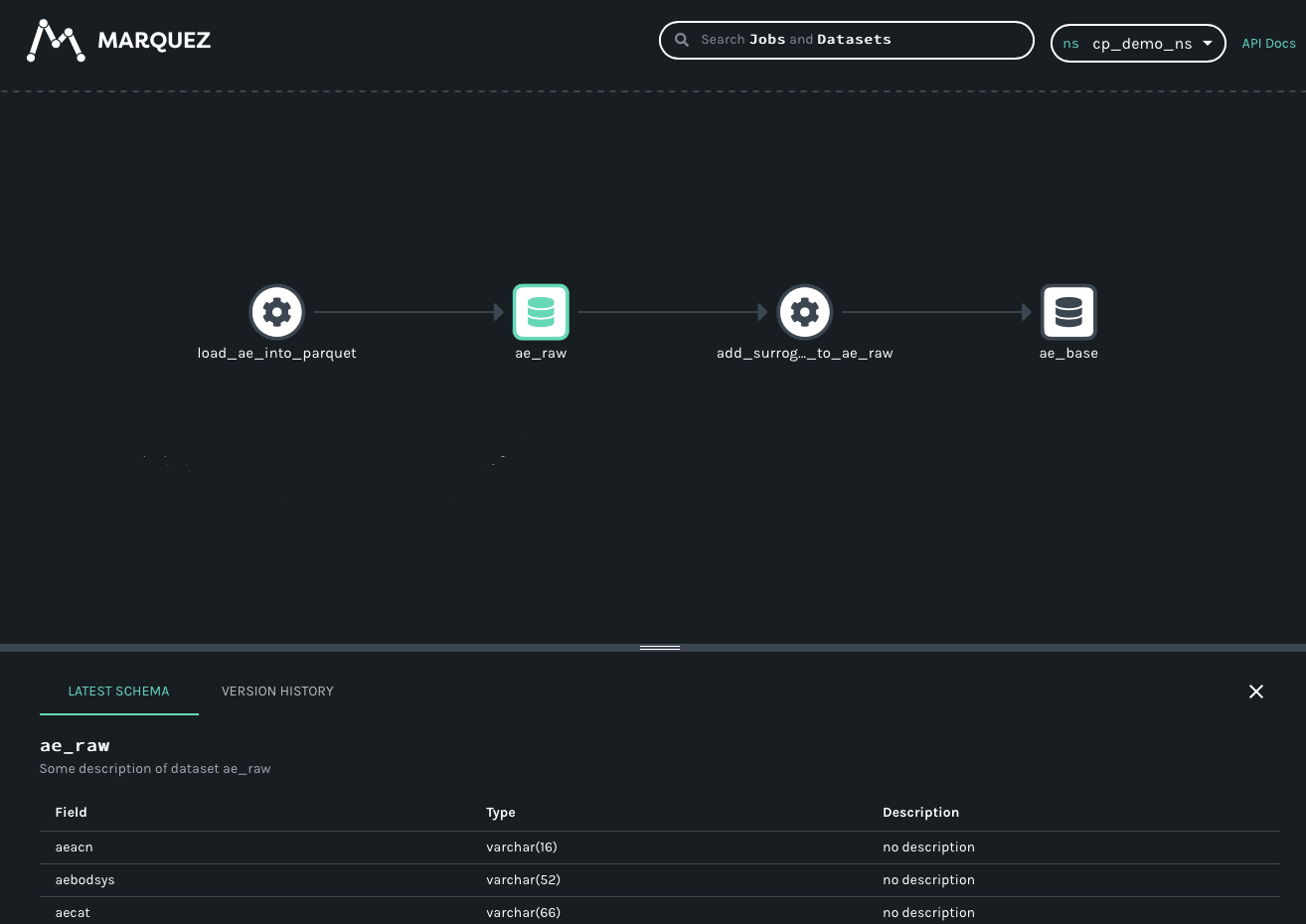
Data products retrieve data from source systems or from other data products, perform transformations and analytical processing and provide access to the results.
Tools for metadata tracking support logging of the corresponding metadata for each of these steps. Thus, they help to retrace and visualize the data flow and the dependencies between incoming and outgoing data.
These tools typically provide the visual representation of a data lineage graph to further support inspecting the processed data.
We often use Marquez, the reference implementation of the Openlineage Standard, for metadata tracking.
Various tools could be used in combination with this tech stack to create Dashboards and visualization graphs.
Within jupyter notebooks, packages like Apache Zeppelin or matplotlib can be used to create data visualization diagrams. Also, through the JDBC endpoints provided by trino
the full range of BI tools (like e.g. Apache Superset, PowerBI, Tableau, Looker, or Sisense) can be used to access data products.
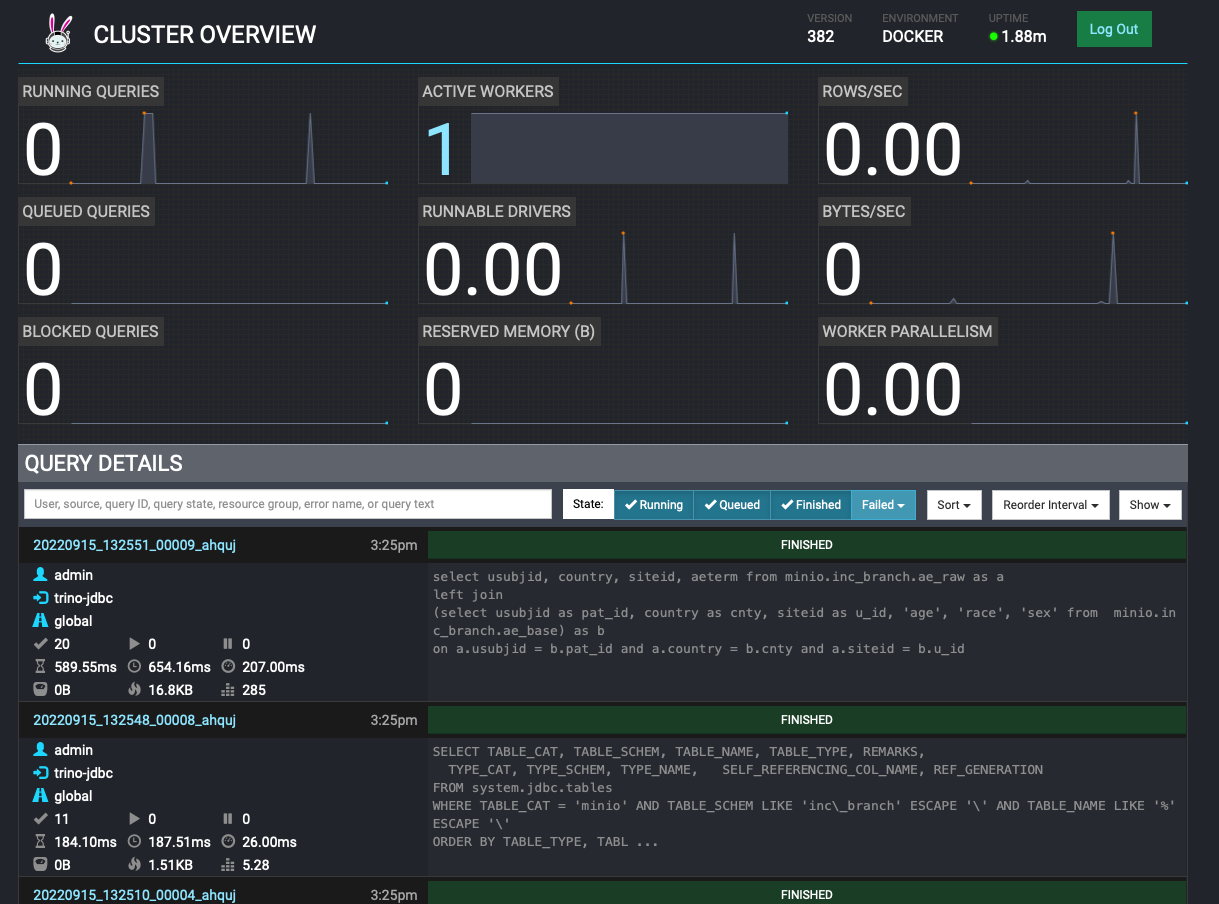
The tech stack can easily be integrated with standard monitoring tools.
lakeFS as well as MinIO offer a Prometheus integration for monitoring purposes.
trino exposes metrics about query execution via JMX, which could be integrated in monitoring solutions like Prometheus.
References
- Official MinIO documentation
- Official lakeFS documentation
- Official trino documentation
- Various lakeFS blogposts to integration of lakeFS with MinIO and Trino
- Prometheus website
- Openlineage website
- Marquez github page
- Jupyter website
- DBeaver website
- Official Apache Zeppelin documentation
- Official matplotlib documentation
- Official Apache Superset documentation
- Official Pandio website
