FAQ
So, what's really behind the hype?
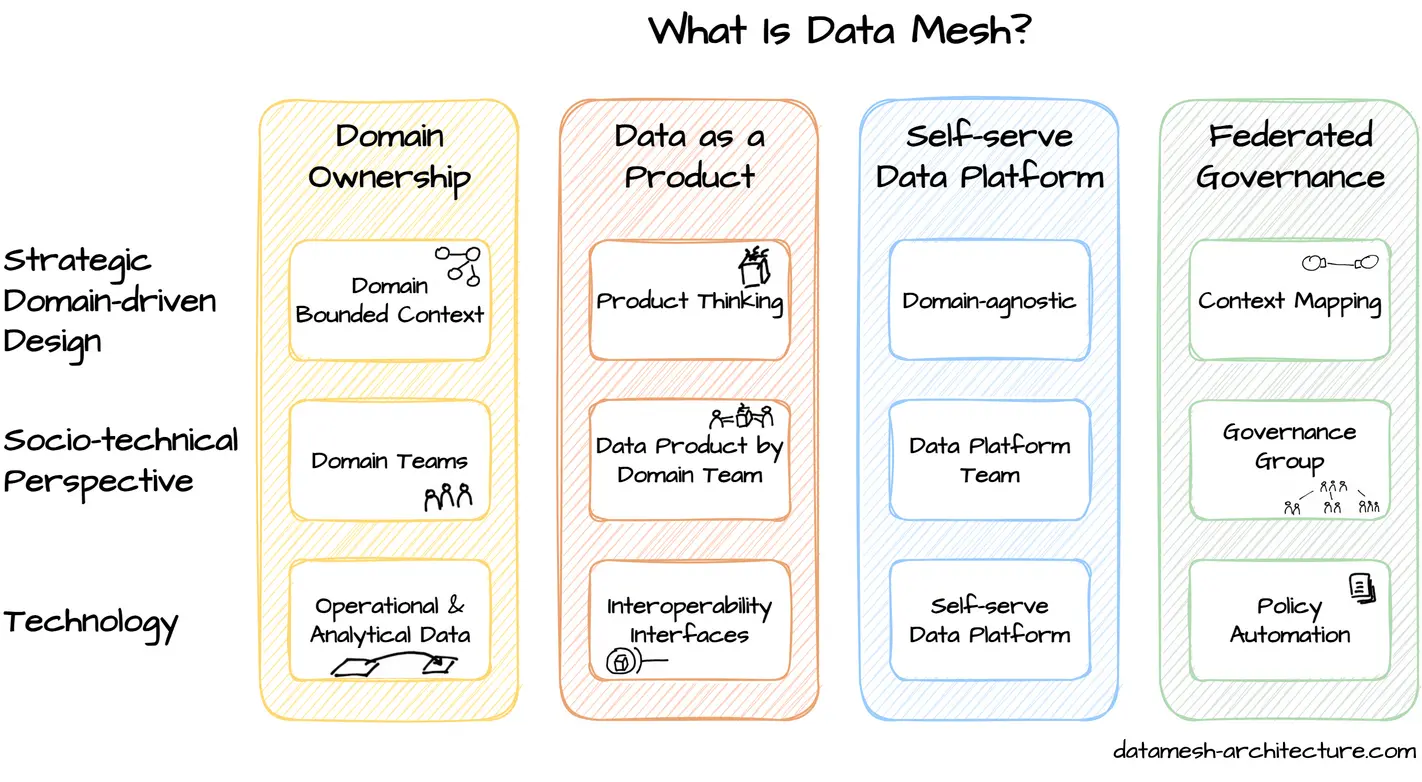
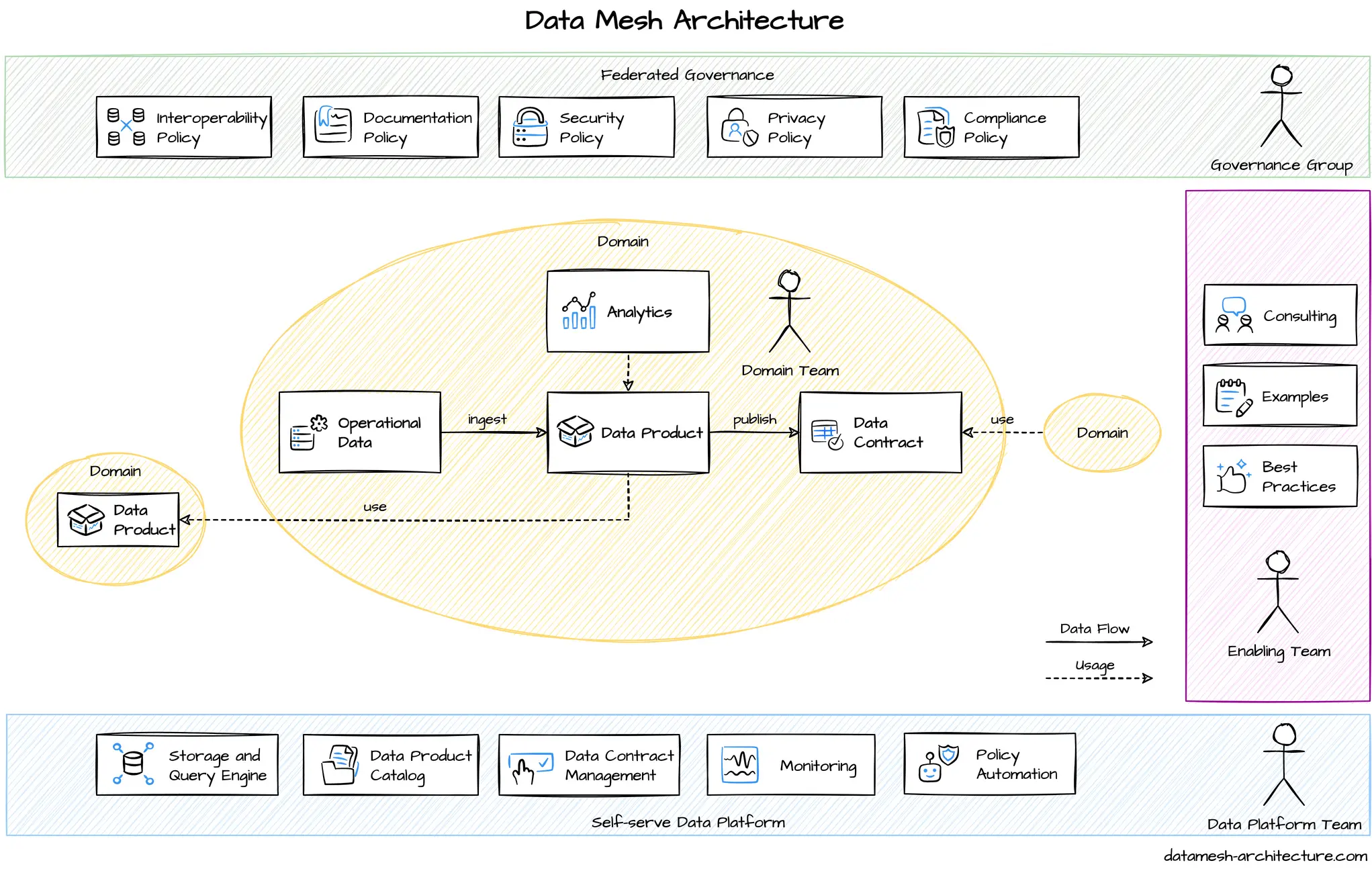
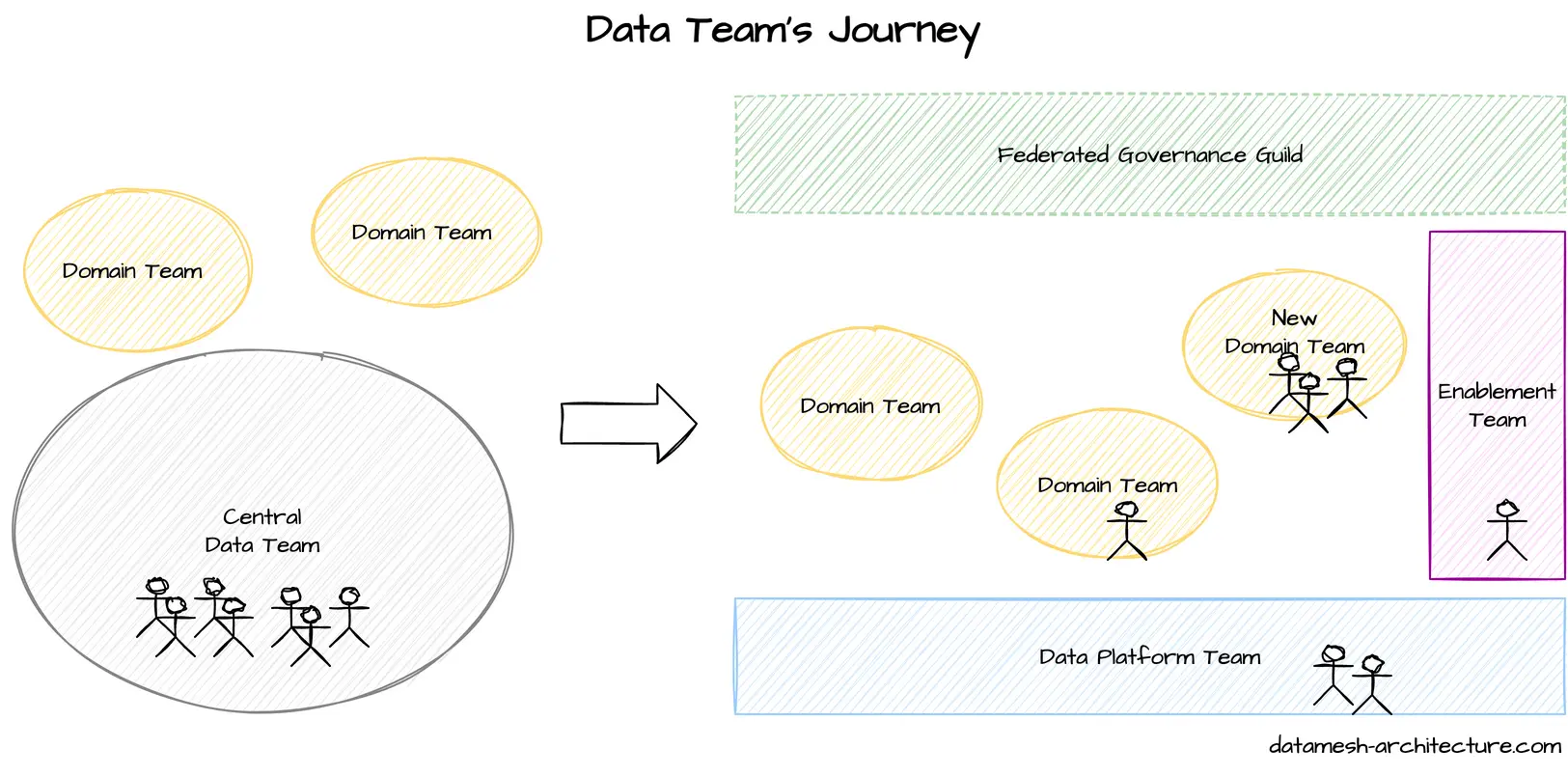
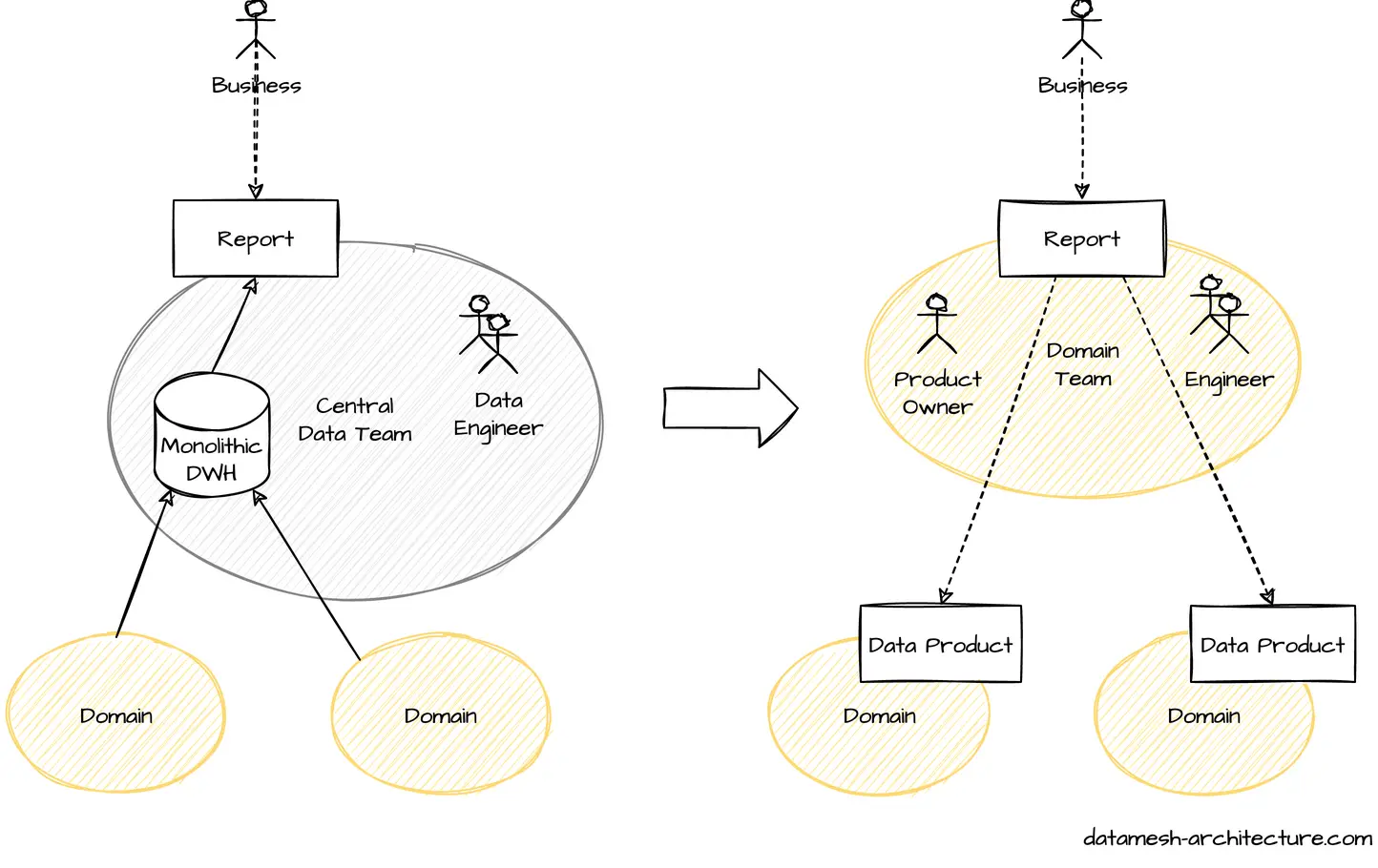
Data mesh is primarily an organizational change.
The responsibilities of data are shifted closer to the business value stream.
This enables faster data-driven decisions and reduces barriers for data-centric innovations.
Who has actually implemented a data mesh?
There is a comprehensive collection of user journey stories from the Data Mesh Learning community
that covers data mesh examples from many different industries.
Is Data Mesh for my company?
It depends, of course.
There are a few prerequisites that should be in place:
You should have modularized your software system following domain-driven design principles or something similar.
You should have a good number (5+) of independent domain teams that have their systems already running in production.
And finally, you should trust your teams to make data-driven decisions on their own.
How to get started?
Start small and agree on the big picture.
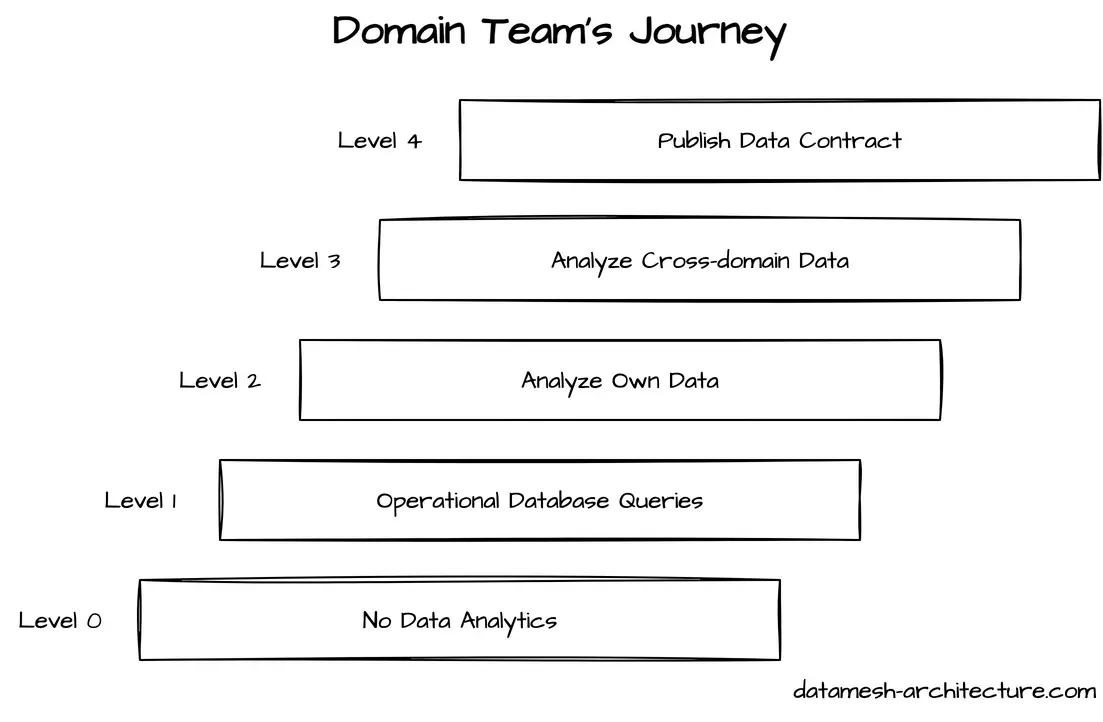
Find two domain teams (that are around level 2) that have a high value use case where one team needs data from the other team.
Let one team build a data product (level 4) and another team use that data product (level 3).
You don’t need a sophisticated data platform yet.
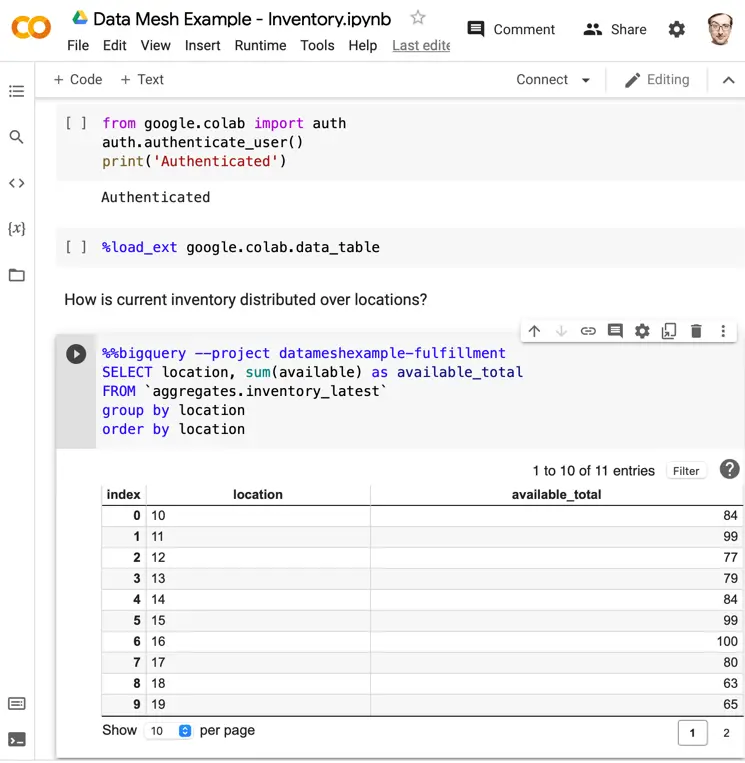
You can start sharing the files via AWS S3, a Git repository, or use a cloud-based database, such as Google BigQuery.
When should I avoid a Data Mesh?
There are some indicators when a data mesh approach might not be suitable for you, including:
- You are too small and don’t have multiple independent engineering teams.
- You have low-latency data requirements. Data Mesh is a network of data. If you need to optimize for low-latency, invest in a more integrated data platform.
- You are happy with your monolithic highly integrated system (such as SAP). It might be more efficient to use their analytical platform.
What is Data Mesh not?
- Data Mesh is not a Silver Bullet.
- Data Mesh is not a religion.
- Data Mesh is not plug-and-play.
- Data Mesh is not a product you can just buy.
- Data Mesh is not a data-only platform.
- Data Mesh cannot be implemented by the data team alone.
- Data Mesh is not a concept for operational data.
- Data Mesh is not data virtualization.
- Data Mesh is not the successor to Data Warehouse or Data Lake.
- Data Mesh cannot be rapidly implemented as Big Bang.
- Data mesh is not a service mesh for data.
- And data mesh has absolutely nothing to do with blockchain.
Is the Data Mesh a generic solution to a distributed data architecture?
No.
By definition, data mesh does not include data products used for serving real-time needs.
Data mesh focuses on analytical use cases.
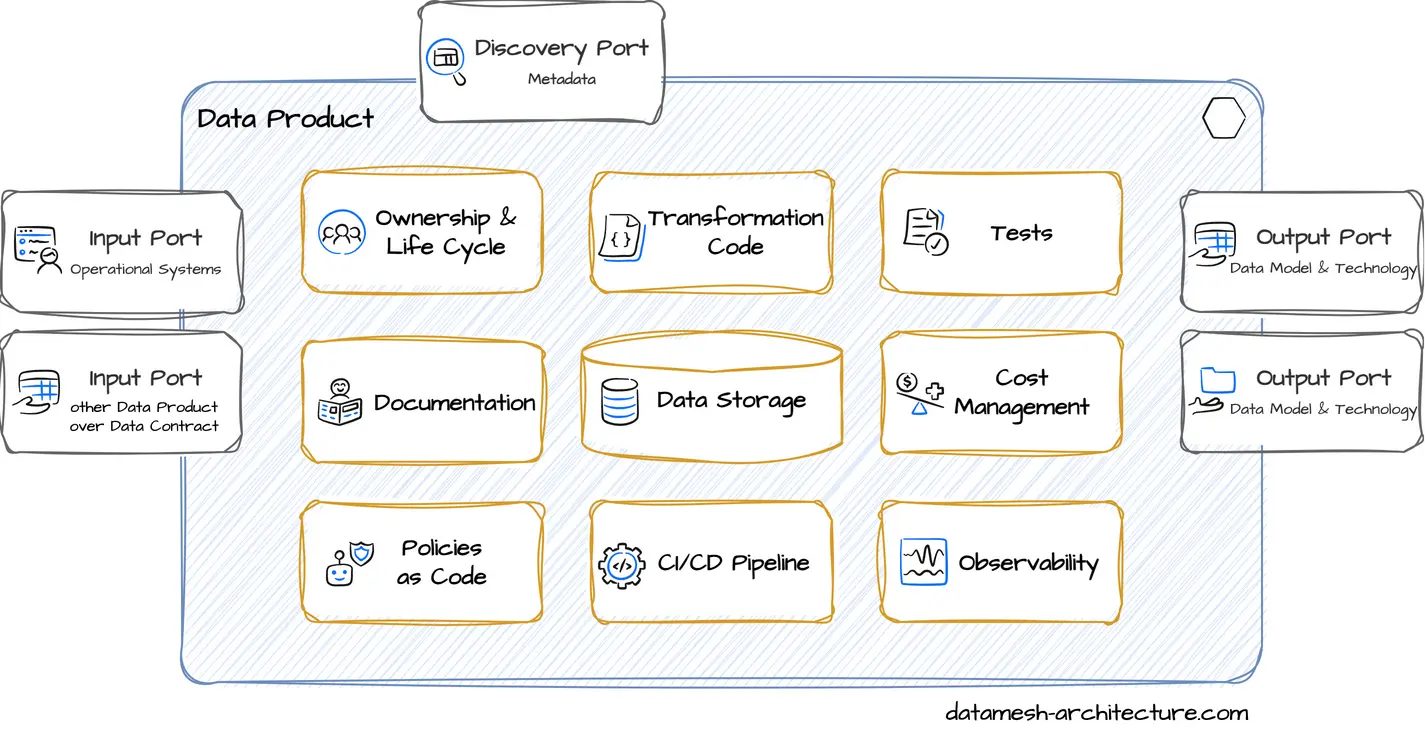
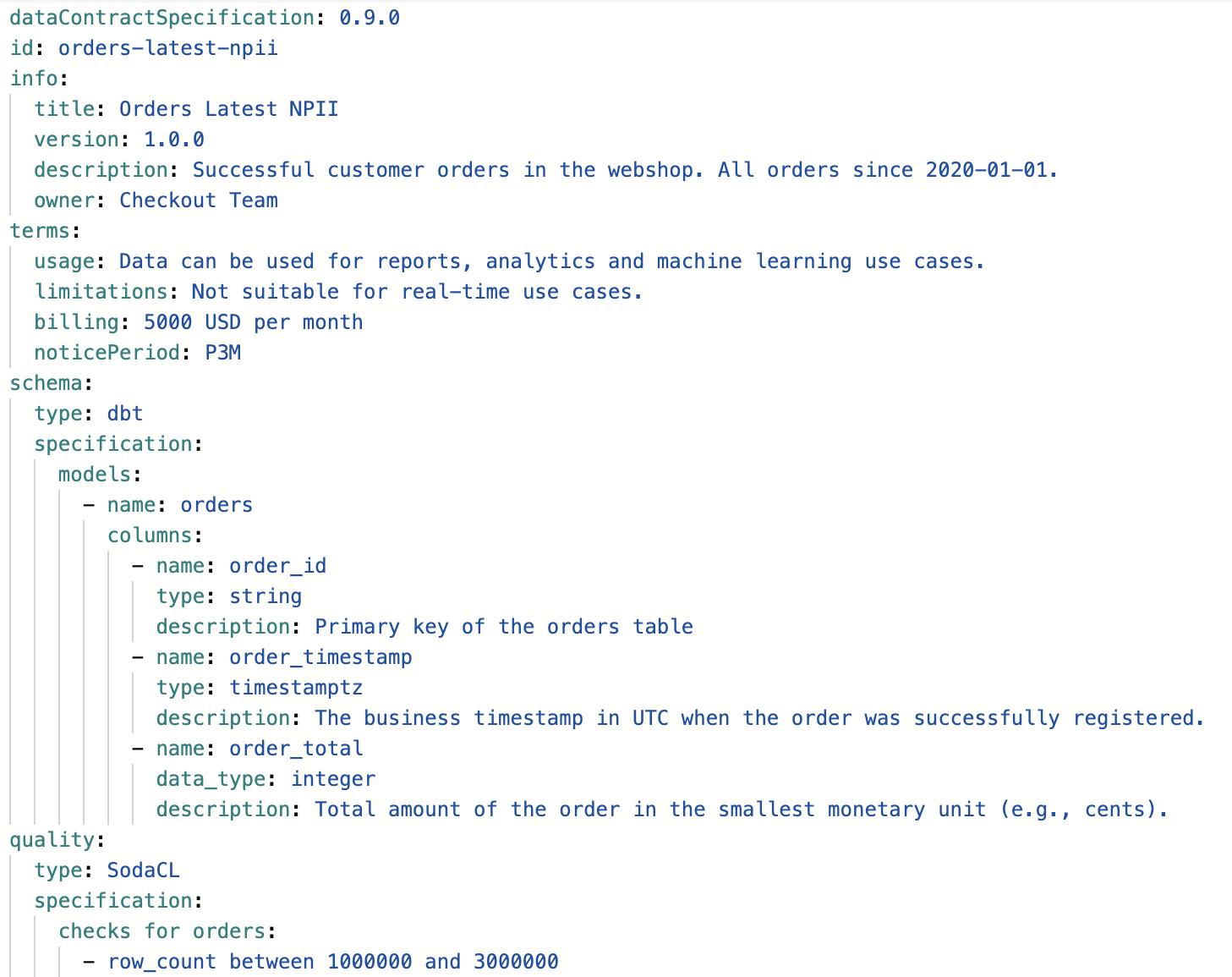
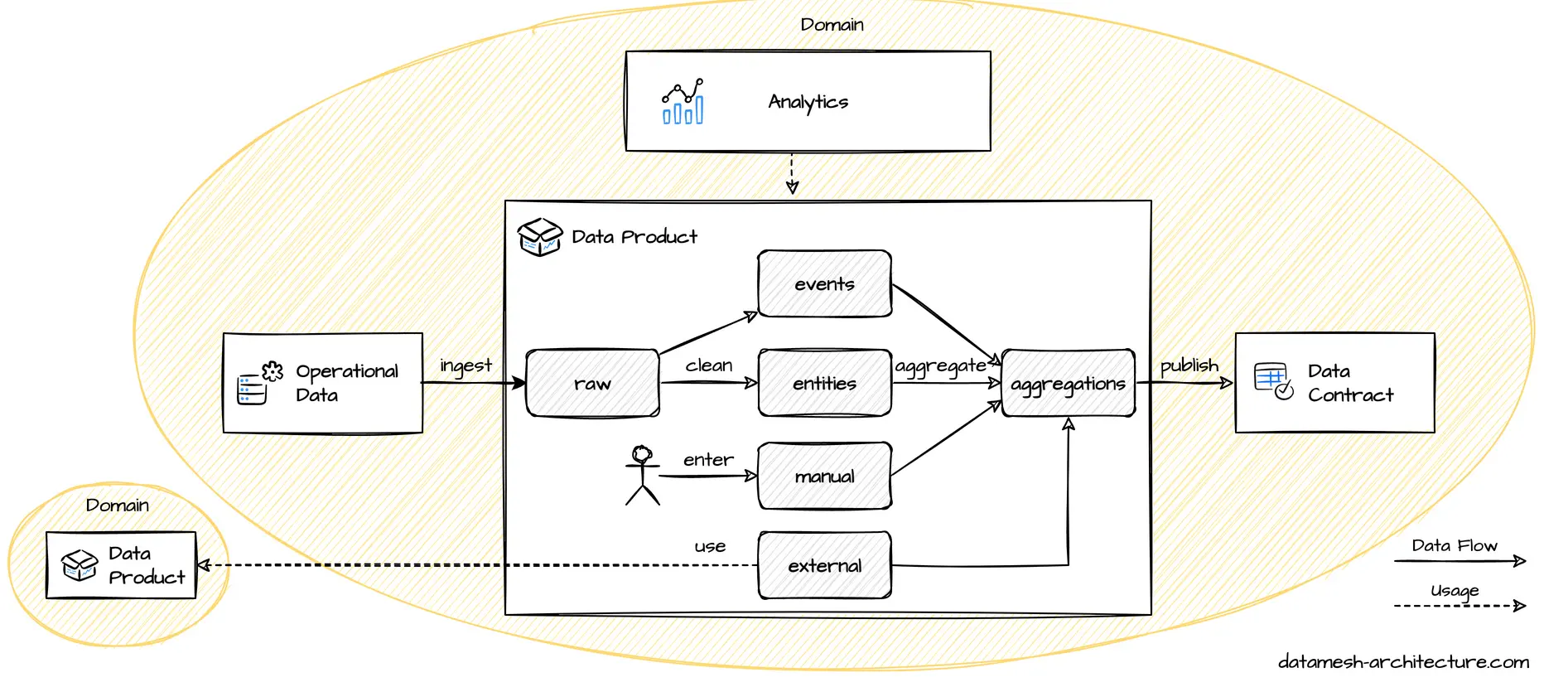
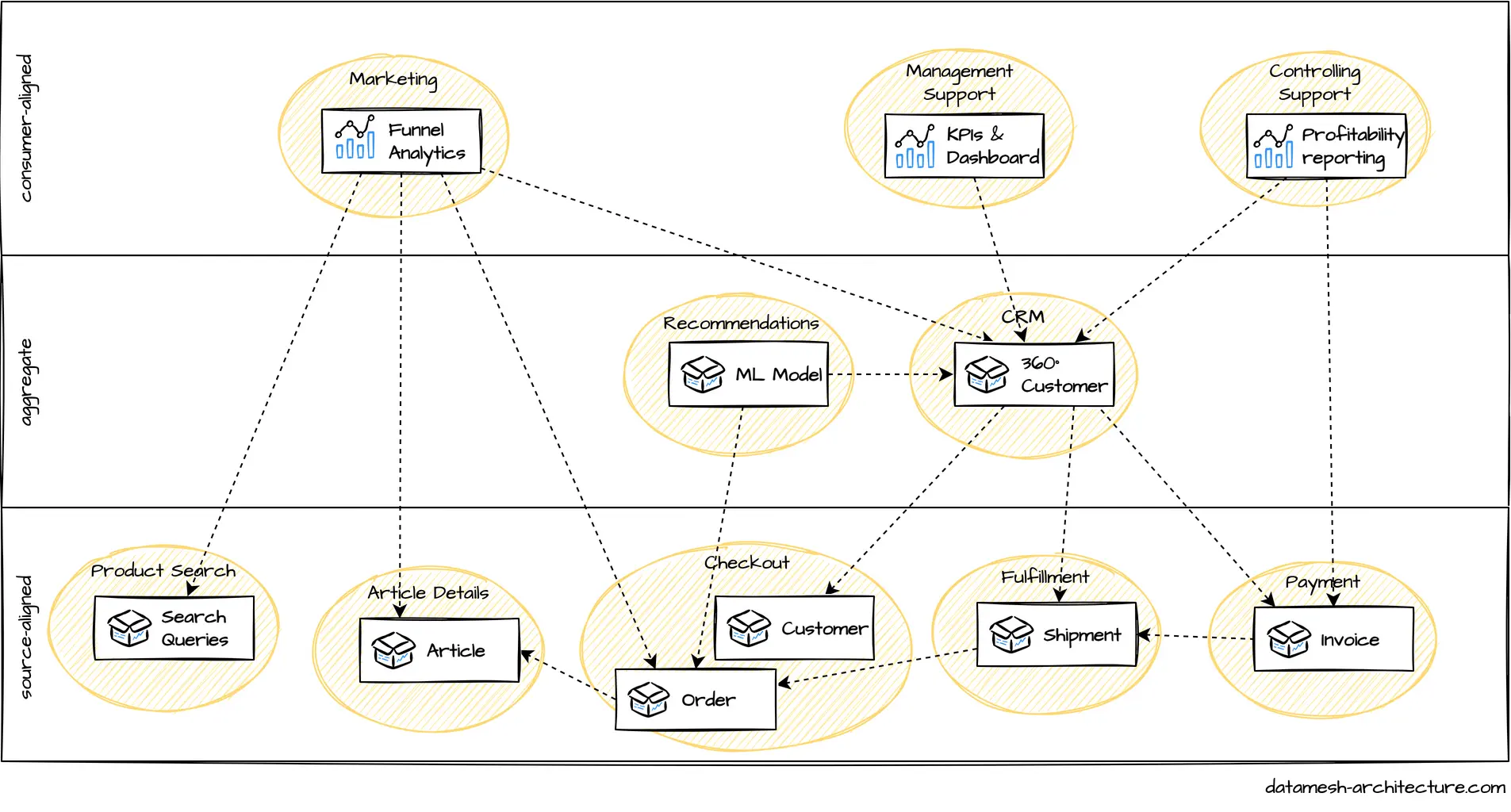
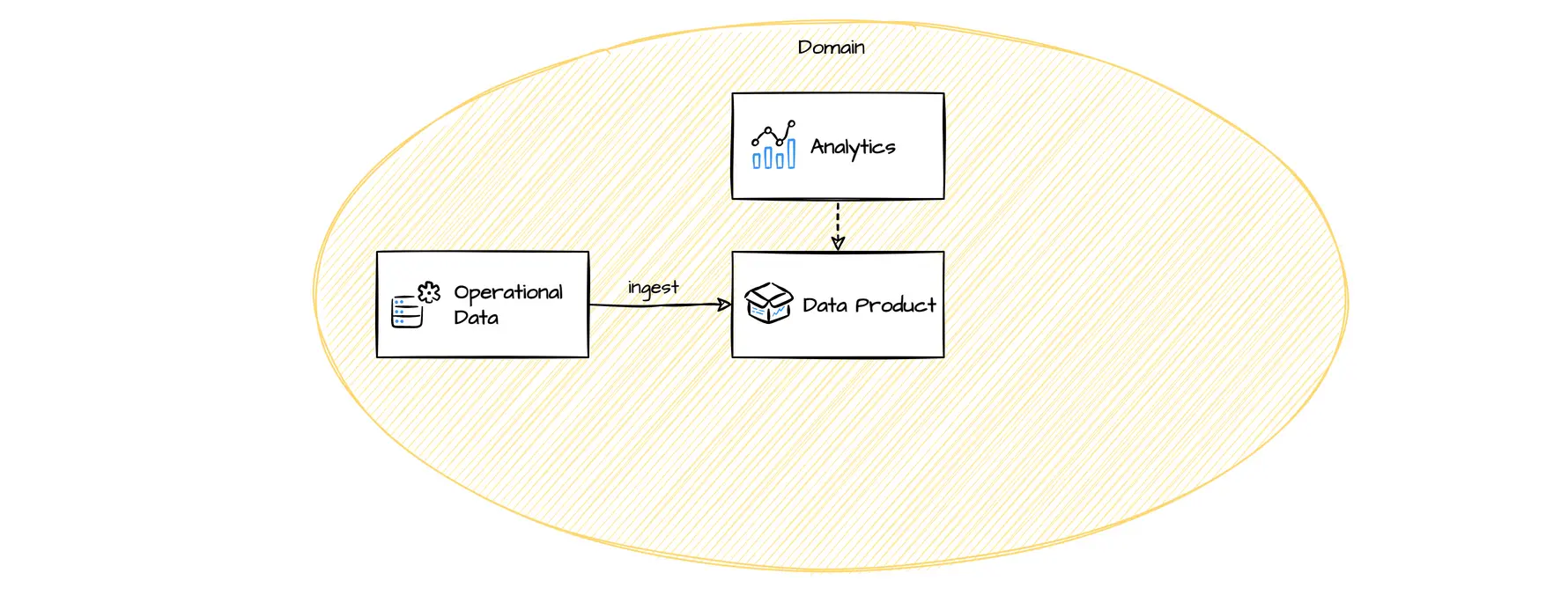
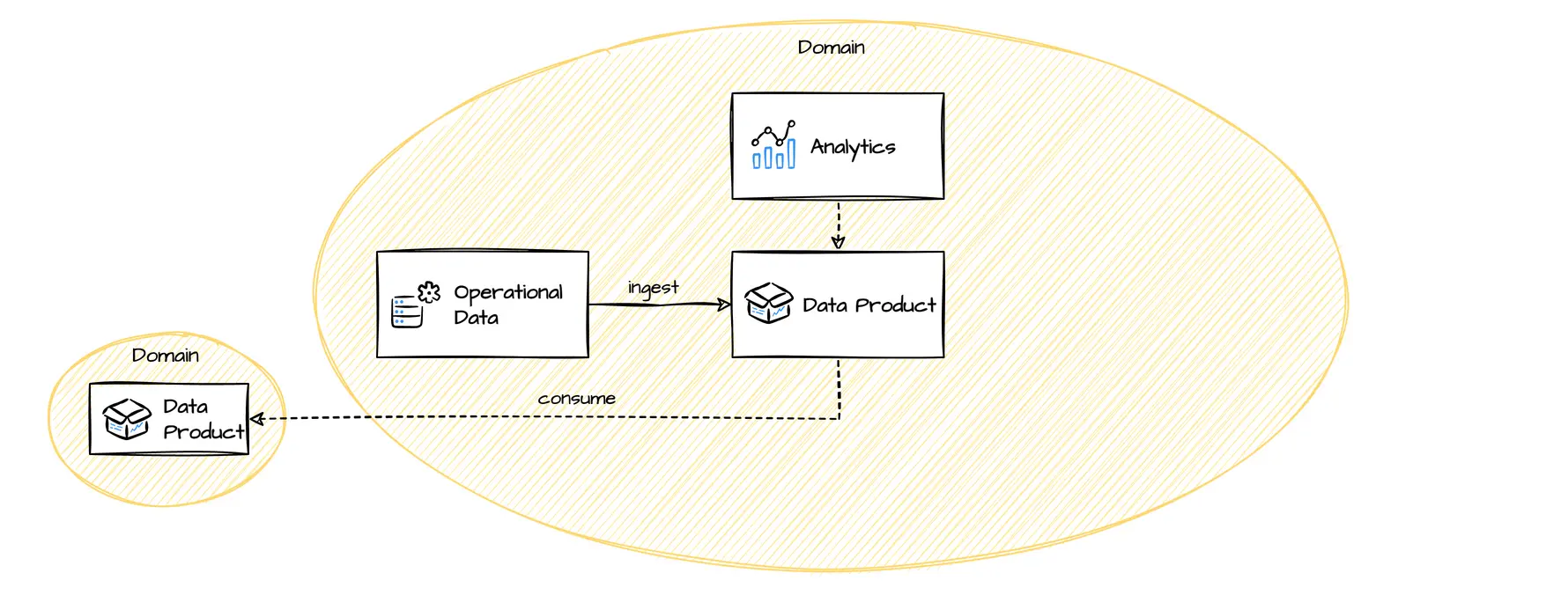
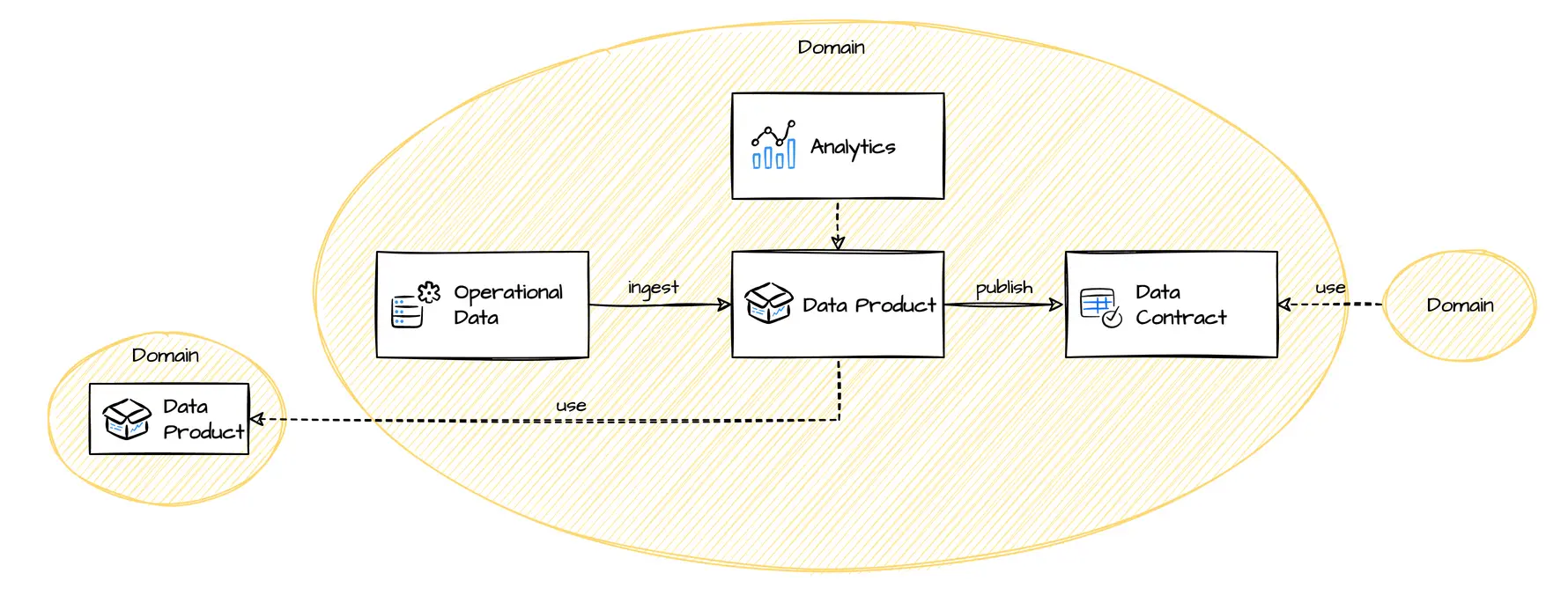
Data Product: What data to include in a data product? Should a data product include other domain's data?
Data that is created and owned by a domain are prime candidates, and the domain team should be encouraged to publish them in an appropriate, cleaned and managed form.
For source-aligned domains, we mostly would argue to include reference IDs.
It is OK to include other domain's data, if the data was transformed, is the basic for business decisions or the exact state of the data at a processing time was relevant. In fact, these are cases, when the processing domain takes ownership for these data based on business cases.
Aggregate domains and consumer-aligned domains can include all foreign data that are relevant for their consumers' use cases.
What's the difference between data mesh and data fabric?
At first, data fabric looks similar to data mesh because it offers a similar self-serve data platform.
Looking deeper, it turns out that data fabric is a central and domain-agnostic approach, which is in strong contrast to the domain-centric and decentralized approach of data mesh.
More in this comparison article .
What might a journey be for teams who operate commercial off-the-shelf (COTS) systems?
Many COTS systems (such as Salesforce, SAP, Shopify, Odoo) provide domain optimized analytical capabilities.
So the journey for domain teams starts directly from level 2.
The challenge is to integrate data products from other domains (level 3, which may be skipped if not needed)
and to publish data products for other domains (level 4).
The system’s data need to be exported to the data platform and managed as data products, conforming the global policies.
As data models evolve with system updates, an anti-corruption layer is a must, e.g., as a cleaning step.
How might externally acquired datasets be part of a data mesh?
Typical examples: Price-Databases or Medical Studies.
A team needs to own this dataset and bring it into the datamesh. If this is not a very technical team, the data-platform should offer an easy self-service to upload files and provide Meta-Data. An Excel API or Google Sheets might also be an option here.
How did you draw the diagrams?
We got this question quite a lot, so we are happy to share our tooling:
We use diagrams.net with "Sketch" style and
Streamline Icons .
We automate the conversion to PNG, SVG and WebP with a little script.
What are your questions?
If you have any more questions, we encourage you to discuss with us on GitHub or reach out to us directly.
But be warned:
Your question might end up in the FAQ. :-)